© 2023 yanghn. All rights reserved. Powered by Obsidian
2.1 数据操作
要点
- 广播机制是为了给形状不同的张量做按元素运算,把两个矩阵扩充为可以运算的更大的矩阵
- 为了减少内存开销,张量更新一般都是原地更新
X:X[:] = X + Y或X += Y
1. 张量
torch.zeros ((2, 3, 4))表示 2 个 3 行 4 列的矩阵,元素全是 0torch.ones((2, 3, 4))表示 2 个 3 行 4 列的矩阵,元素全是 1torch.randn(3, 4)表示 3 行 4 列、其中的每个元素都从均值为0、标准差为1的标准高斯分布(正态分布)中随机采样。
1.1 访问元素
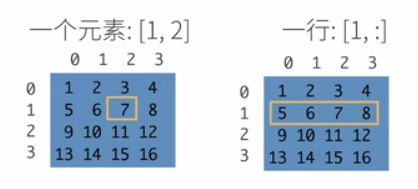
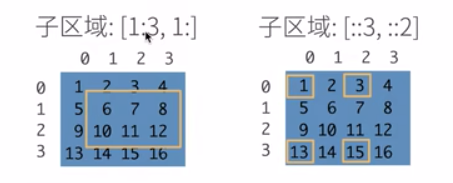
1.2 改变张量形状:
X.reshape(-1): 张量变成向量,按照行的方向排列,若按照列的方向排列,则应该为X.T.reshape(-1):
import torch
# 创建一个形状为 (2, 3) 的二维张量
X = torch.tensor([[1, 2, 3],
[4, 5, 6]])
# 使用 .reshape(-1) 将其转换为一维张量
Y1 = X.reshape(-1)
Y2 = X.T.reshape(-1)
print(Y1) #[1, 2, 3, 4, 5, 6]
print(Y2) #[1, 4, 2 ,5, 3, 6]
而对于高维张量,可以理解为从左到右依次按当前维度堆叠
1.3 张量重排
permute函数用于重新排列多维张量的维度。重排后可以方便用在for循环里(for循环只会对第一个维度循环),将(批量大小,其他维度)转化为(其他维度,批量大小)
# 创建一个形状为(2, 3, 4)的张量
x = torch.randn(2, 3, 4)
# 使用.permute()重排维度
x_permuted = x.permute(2, 0, 1)
print(x_permuted.shape)
2 张量计算
1.1 张量常见计算
-
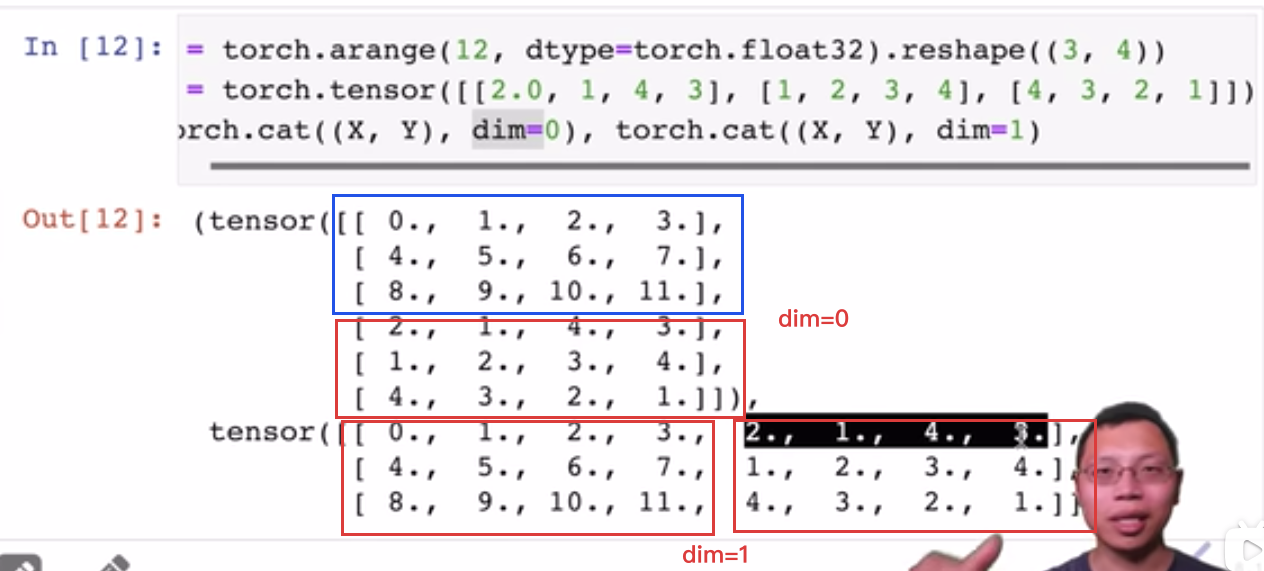
torch.cat ((X, Y), dim=0):把两个张量堆叠起来,dim=1表示左右放置,dim=0表示上下放置,dim含义详见 Pandas 拾遗#^540216 :
-
torch.stack:将一系列张量沿着一个新的维度堆叠起来。不同于torch.cat,它不是简单地将张量拼接在一起,而是在指定的维度上创建了一个新的维度:
import torch
# 创建两个形状为(3, 4)的张量
tensor1 = torch.randn(3, 4)
tensor2 = torch.randn(3, 4)
# 使用torch.stack在一个新的维度上堆叠这两个张量
stacked_tensor = torch.stack((tensor1, tensor2), dim=0)
print(stacked_tensor.shape)
# (2, 3, 4)
1.2 广播机制
可以参考官方手册[1]
1.2.1两个张量可以被广播的的原则
如果两个张量 X Y 可以广播,必须遵循下面两个原则:
- 这两个张量都至少有一个维数大于等于 1 的维度(维度为 (0,0) 不行,这两个维度都是 0)
- 对这两个张量的维度,从尾部开始(右往左)逐一比较,要么相等、要么有一个等于 1、要么有一个不存在
x=torch.empty(5,7,3)
y=torch.empty(5,7,3)
# 维数相等,可以广播
x=torch.empty((0,))
y=torch.empty(2,2)
# x 不存在大于等于 1 的维度,不能广播
x=torch.empty(5,3,4,1)
y=torch.empty( 3,1,1)
# 逐一比较,满足上面条件 2,可以广播
x=torch.empty(5,2,4,1)
y=torch.empty( 3,1,1)
# 逐一比较,2!=3,不能广播
1.2.2 被广播后的张量运算
如果两个张量 X Y 可以广播,运算后 Z 的维度为:
- 如果 X 维度少,少的维度用 1 补齐
- 运算结果 Z 的各个维度取 X Y 各个维度的最大值
x=torch.empty(5,1,4,1)
y=torch.empty( 3,1,1)
(x+y).size()
# torch.Size([5, 3, 4, 1])
x=torch.empty(1)
y=torch.empty(3,1,7)
(x+y).size()
# torch.Size([3, 1, 7])
x=torch.empty(5,2,4,1)
y=torch.empty(3,1,1)
(x+y).size()
# 不能被广播
1.3 原地更新
- 可以利用
id函数返回一个对象的唯一标识符,通常是该对象在内存中的地址,来判断前后两次是不是同一块内存地址 - 例子
Y = X + Y前后两次 Y 是两块内存地址,深度学习过程中需要经常做这种操作,这样会极大浪费内存 - 原地更新方法:
Y[:] = X + Y或者Y += X**- 利用以下划线结尾的方法实现原地更新,例如:
import torch
# 创建一个张量
x = torch.tensor([1, 2, 3])
x.add_(1) # 使用原地操作将张量中的每个元素加上 1
print(x) # 输出: tensor([2, 3, 4])
x.add(1) # 创建一个新的张量对象来保存结果,并返回这个新的张量对象,而不会修改原始张量 `x`。
print(x) # 输出: tensor([2, 3, 4])
3. 梯度相关
detach:
pytorch 的 detach
在PyTorch中,detach()方法是用于将一个变量从当前的计算图中分离出来,返回一个新的Variable,这个新变量和原变量共享相同的数据,但是不会在其上执行梯度计算。即使之后对这个新变量进行操作,也不会影响到原来计算图中的梯度传播。
例如:
import torch
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x * 2
z = y.mean()
z.backward() # 反向传播计算梯度
print(x.grad) # 输出: tensor([0.6667, 0.6667, 0.6667])
# 使用detach创建新的不追踪梯度的变量
new_tensor = y.detach()
print(new_tensor) # 输出: tensor([2., 4., 6.]) 这个操作不会影响原来tensor的梯度传递
# 对这个新的tensor进行操作
new_tensor += 1
print(new_tensor) # 输出: tensor([3., 5., 7.])
# 因为已经detach了,所以对new_tensor的操作不会影响x的梯度
print(x.grad) # 输出: tensor([0.6667, 0.6667, 0.6667])
# 如果没有使用detach,则下面这行代码会抛出错误,
# 因为PyTorch不允许在requires_grad=True的variable上进行in-place操作。
# y += 1 # 抛出 RuntimeError